Aurélien Bossard
Maître de conférences en informatique, j’effectue mes recherches au LIASD et mes enseignements au département informatique de l’IUT de Montreuil - Université Paris 8. J’effectue majoritairement mes recherches en traitement automatique du langage, en particulier en résumé automatique.

J’ai soutenu ma thèse, dirigée par Thierry Poibeau et intitulée “Contribution au résumé automatique multi-documents” le 12 juillet 2010 (mention très honorable). Manuscrit de la thèse (format pdf)
Vous trouverez sur ce site des articles que j’ai publiés, un démonstrateur de résumé automatique, une rubrique “Le résumé automatique pour les nuls”, qui vise à faire comprendre à ceux qui le souhaitent des méthodes qui concernent mon domaine de recherche ainsi que divers outils dédiés à l’accessibilité de l’information.
L’outil “Les mots de l’actu” (voir les descriptions de l’outil, de ses mises à jour ou de son développement) fournit sous forme d’un nuage de mots les mots les plus représentatifs de l’actualité des 24 dernières heures. Il fournit également un un aperçu et un lien vers les articles qui les représentent le mieux afin de proposer un point d’accès original aux actualités les plus importantes du jour.
Publications
2020
- Aurélien Bossard, David Stéphane Belemkoagba, Abdallah Essa, Valentin Nyzam, Christophe Rodrigues and Kevin Sylla. “Génération de résumés abstractifs de commentaires sportifs”
TextMine 2020 (TM’2020) - En conjonction avec EGC 2020 - 27 - 31th January 2020, Brussels, Belgium.
2019
- Valentin Nyzam, Aurélien Bossard. “A Modular Tool for Automatic Summarization”
ACL 2019 Demonstrations - Association for Computational linguistics- 28th July - 2nd August 2019, Firenze, Italy. pdf
2018
- Valentin Nyzam, Christophe Rodrigues, Aurélien Bossard. “Un outil modulaire pour le résumé automatique”
TALN 2018 - Conférence sur le Traitement Automatique du Langage Naturel - 14-18 mai 2018, Rennes, France. pdf
2017
- Aurélien Bossard, Christophe Rodrigues. “An Evolutionary Algorithm for Automatic Summarization”
RANLP 2017 - Recent Advances in Natural Language Processing- 2-8 septembre 2017, Varna, Bulgarie. pdf - Aurélien Bossard, Valentin Nyzam. “Un outil modulaire libre pour le résumé automatique”
TALN 2017 - 24ème Conférence sur le Traitement Automatique des Langues Naturelles - Démonstrations - 26-30 juin 2017 - Orléans, France - Aurélien Bossard, Nathan Gatto, Valentin Nyzam. “Résumer automatiquement en ligne : démonstration d’un service web de résumé multidocument”
TALN 2017 - 24ème Conférence sur le Traitement Automatique des Langues Naturelles - Démonstrations - 26-30 juin 2017 - Orléans, France
2016
- Aurélien Bossard, Mario Cataldi, Myriam Lamolle and Chan Le Duc. “Evaluation et Prédiction de la Centralité de Groupes de Recherche dans un Réseau de Collaborations scientifiques”
EGC 2016 - 16ème Conférence Internationale sur l’Extraction et la Gestion de Connaissances - 18-22 janvier 2016 - Reims, France
2015
- Aurélien Bossard and Christophe Rodrigues. “Une approche évolutionnaire pour le résumé automatique” pdf
TALN 2015 - 22ème Conférence sur le Traitement Automatique des Langues Naturelles - 22-25 juin 2015 - Caen, France - Aurélien Bossard and Christophe Rodrigues. “ROBO : une mesure d’édition pour la comparaison de phrases - Application au résumé automatique” pdf
TALN 2015 - 22ème Conférence sur le Traitement Automatique des Langues Naturelles - 22-25 juin 2015 - Caen, France
2013
- Aurélien Bossard. “Generating Update Summaries : Using an Unsupervized Clustering Algorithm to Cluster Sentences” pdf
Theory and Applications of Natural Language
Processing. Springer, 2013.
2012
- Aurélien Bossard and Émilie Guimier De Neef. “Le résumé par classification - Principes et applications”
Ed. Hermès, Résumé automatique de documents
Revue Document Numérique, vol. 15 no 2. Pages 11–39
2011
- Aurélien Bossard et Emilie Guimier De Neef
“Ordonner un résumé automatique multidocument fondé sur une classification des phrases en classes lexicales”
TALN 2011 - 27 juin - 1er juillet 2011 - Montpellier, France - Aurélien Bossard et Emilie Guimier De Neef
“Etude de l’impact du regroupement automatique de phrases sur un système de résumé multi-documents” pdf
CORIA 2011 - 16/18 mars 2011 - Avignon, France - Emilie Guimier De Neef, Aurélien Bossard, Frédéric Gavignet et Olivier Collin
“Un outil de géolocalisation et de résumé automatique pour faciliter l’accès à l’information dans des corpus d’actualité”
EGC 2011, session démonstrations - 23 janvier 2011 - Brest, France - Aurélien Bossard
“Génération de résumés de mise à jour : Utilisation d’un algorithme de classification non supervisée pour détecter la nouveauté dans les articles de presse” pdf
Atelier CIDN d’EGC 2011 - 22 janvier 2011 - Brest, France - Aurélien Bossard
“Generating Update Summaries: Using an Unsupervized Clustering Algorithm to Cluster Sentences” pdf
Theory and Applications of Natural Language Processing Springer - 2011 - Aurélien Bossard, Michel Généreux et Thierry Poibeau
“Générer des résumés d’opinion”
Revue Traitement Automatique du Langage vol. 51 n°3 “Opinions, Sentiment and Subjectivity” - 2011 - Aurélien Bossard et Christophe Rodrigues
“Combining a Multi-document Summarization System – CBSEAS – with a Genetic Algorithm” pdf
Smart Innovation, Systems and Technologies vol. 8 - Springer - isbn 978-3-642-19617-1 - 2011
2010
- Aurélien Bossard et Christophe Rodrigues
“Combining a Multi-document Summarization System with a Genetic Algorithm on the darknet”
CIMA 2010 - 27-29 octobre 2010 - Arras, France - Aurélien Bossard
“Contribution au résumé automatique multi-documents” pdf
Thèse de doctorat - Directeur : Thierry Poibeau - Laboratoire d’informatique de Paris-Nord - 12 juillet 2010
2009
- Aurélien Bossard et Thierry Poibeau
“Integrating Document Structure to an Automatic Summarizer” pdf
RANLP 2009 - 14-16 September 2009 - Borovets, Bulagaria
Aurélien Bossard
“CBSEAS, a New Approach to Automatic Summarization”
SIGIR 2009 - Doctoral Consortium - 19-23 juillet 2009 - Boston, USA - Aurélien Bossard
“Une approche mixte-statistique et structurelle - pour le résumé automatique de dépêches” pdf
TALN 2009 - 24-26 Juin 2009 - Senlis, France - Michel Généreux et Aurélien Bossard
“Résumé automatique de textes d’opinion” pdf
TALN 2009 - 24-26 Juin 2009 - Senlis, France - Aurélien Bossard, Michel Généreux et Thierry Poibeau
“CBSEAS, a Summarization System - Integration of Opinion Mining Techniques to Summarize Blogs” pdf
EACL 2009, System Demonstration - 30 March-3 April 2009 - Athens, Greece.
2008
- Aurélien Bossard, Michel Généreux et Thierry Poibeau
“Description of the LIPN Systems at TAC2008: Summarizing Information and Opinions” pdf (présentation pdf)
Text Analysis Conference 2008, Workshop on Summarization Tracks - 17-19 novembre 2008 - National Institute of Standards and Technology, Gaithersburg, Maryland USA - Aurélien Bossard et Thierry Poibeau
“Regroupement automatique de documents en classes événementielles” pdf (présentation pdf)
TALN 2008 - 07/06/2008 - Avignon, France
2007
- Aurélien Bossard et Thierry Poibeau
“Adaptation d’une ressource prédicative pour l’extraction d’information” pdf
LGC 2007 - 02/10/07 - Bonifacio, France - Aurélien Bossard
“Vers une ressource prédicative pour l’extraction d’information” pdf (présentation pdf)
Recital 2007 - 05/06/07 - Toulouse, France
Recherches
Mes recherches ont principalement porté sur le résumé automatique multidocument par extraction. J’ai étudié le résumé automatique fondé sur le regroupement automatique des phrases à résumer. Les regroupements créés, fondés sur une approche statistique du vocabulaire des phrases, véhiculent une composante spécifique de l’information à résumer. Partant de l’hypothèse que les phrases d’un même groupe sont porteuses d’informations similaires, une seule phrase de chaque groupe est sélectionnée comme phrase candidate à l’extraction dans le résumé. Cela permet dans le même temps d’éliminer la redondance, et de sélectionner les informations les plus centrales. Par ailleurs, le regroupement de phrases permet non seulement d’évaluer la centralité d’une phrase (l’importance de ses informations) vis-à-vis du contenu global du ou des documents à résumer, mais également vis-à-vis du contenu local à sa classe. Cet article présente l’intérêt du regroupement automatique de phrases préalable à leur extraction et de l’intégration du calcul de centralité locale au calcul de la centralité d’une phrase.
Un résumé ainsi généré comporte les informations essentielles du ou des documents d’origine, mais sa lecture peut être difficile, à cause notamment de marqueurs logiques ou temporels extraits de leur contexte ou d’incohérences liées au temps verbaux utilisés, mais également en raison de l’ordre des phrases extraites. C’est pourquoi je me suis intéressé au réordonnancement de résumé, afin de produire des résumé dont l’ordre des phrases reflète une logique soit temporelle, soit causale, et ainsi plus compréhensible pour le lecteur.
Exemple d’un résumé automatique généré par la méthode CBSEAS, développée pendant ma thèse :
Le laboratoire français antidopage de Châtenay-Malabry (LNDD) avait procédé à une analyse d’échantillons contenant de l’EPO dont six ont été attribués par le journal au coureur américain.
L’Américain Lance Armstrong, septuple vainqueur du Tour de France qui a annoncé dernièrement son retour à la compétition en 2009 dans l’équipe Astana, a repoussé, mercredi 1er octobre, la proposition de l’Agence française de lutte contre le dopage (AFLD) de procéder à une nouvelles analyse des échantillons prélevés pendant le Tour de France 1999 “pour couper court aux rumeurs qui le concernent si elles sont infondées”.
Résumé de l’affaire Armstrong en 2009, où celui-ci était accusé de s’être dopé avant son premier arrêt de compétition (120 mots maximum, ponctuation comprise)
J’ai participé aux campagnes d’évaluation TAC (Text Analysis Conference) 2008 - tâches Update et Opinion pilot - et TAC 2009 - tâche Update - et donc développé un axe de recherche plus applicatif, guidé par la tâche. Le résumé de mise à jour (Update) consiste à résumer, sachant les documents que l’utilisateur a déjà lus, les informations comprises dans les documents qu’il n’a pas encore lus dont il n’a pas pu prendre connaissance en lisant les documents précédents.
CV (eng)
Aurélien Bossard
Ph.D. in Computer Science
- France
- Webpage : http://www.aurelienbossard.fr
- 32 years old, driving license, personal vehicle
University Curriculum
2006-2010
Ph.D. in Computer Science, Université Paris 13 - Institut Galilée, Villetaneuse, “Contribution to Automatic Multidocument Summarization”.
Supervized by Thierry Poibeau, mention “très honorable”.
2004-2006
Master degree in Computer Science, Université Paris 13 - Institut Galilée, Villetaneuse, “Towards a Predicative Lexicon For Information Extraction”, Grade B pass, ranked 2nd.
2003-2004
Bachelor’s degree in Computer Science, Université Paris 13 - Institut Galilée, Villetaneuse.
Experience
Professional Curriculum
2011-2012
Lecturer, IUT de Montreuil - University Paris 8 - LIASD, Montreuil (93)
Research on Automatic Summarization :
- Development of new sentence similarity metrics for sentence selection ;
- Development of a new summarization algorithm using genetic algorithm ;
Work environment : Java, Perl, Python - Linux
Research on sports training planification :
- Development of a training planning platform ;
- Collaborative work with Wiener Universität ;
Work environment : PHP, MySQL, Javascript - Linux
2011-2012
Postdoctoral Fellowship, LIMSI - CNRS, Orsay (91)
- Research on named entity (NE) recognition in a multilingual context :
- Development of corpora sampling tools ;
- Development of named entities transfer from one language to another, using parallel corpora ;
- Collaborative work on automatic acquisition of NEs annotation rules.
Work environment : C/C++, Perl, Python - Linux - Git
2010-2011
Postdoctoral Fellowship / Research Engineer, Orange Labs, Lannion (22)
Research on automatic summarization (AS) :
- Development of a news AS prototype ;
- Collaborative work on persons presentation;
- Workshop on synthetic presentation of politic interventions during 2012 presidential campaign.
Work environnement : Java, Perl, Python, XHTML - Linux, Windows - Eclipse
2009-2010
“Attaché temporaire d’enseignement et de recherche”, LIPN - Université Paris 13 & CNRS, Villetaneuse (93)
- Research on automatic summarization (AS), teachings at the “IUT de Villetaneuse” :
- AS platform optimization using a distributed genetic algorithm ;
- Master internship management;
- Teachings : Systems/Network, 2nd sem (36h) ; Architecture, 1st sem (36h) ; Web prog, 3rd sem (24h).
Work environment : Java, C/C++, Perl - Linux - Eclipse
2006-2009
Doctoral fellowship , LIPN - Université Paris 13 & CNRS, Villetaneuse (93)
Research on automatic multidocument summarization :
- Strategizing a new multidocument AS method ;
- Development of a news AS platform ;
- Development of a blog opinion oriented AS platform (collaborative work)
- Participation in TAC AS evaluation campaign ;
- Development of a distributed genetic algorithm (for AS optimization)
- Participation in Infom@gic project (part of Cap Digital) ;
- Teaching (Institut Galilée’s computer science dpt) : Imperative prog, 2nd sem (2x 50h) ; Imperative prog, 4th sem (36h) ; NLP Project, 2nd sem (12h) ; System/Network, 2nd sem (12h) ; Professional project, 1st sem (14h) ; Software Engineering, 2nd sem (16h).
Work Environment : Java, C/C++, Perl, Matlab - Linux - Eclipse
2006
Master Internship, LIPN - Université Paris 13 & CNRS, Villetaneuse (93)
Research on information extraction using predicative lexicon.
Work environment : SQL, Perl - Linux - Unitex
July/August 2005
Internship, Napier University, Edinburgh (UK)
Internship on thermal captors signal processing :
- Development of captor’s protocol analysis tools ;
- Development of a thermal picture zones discrimination tool.
Work environment : C/C++ - Windows - Studio
Misc
2007-2013
Web developer / Webmaster
Development and administration of several websites, urls on demand.
Work environment : php, html, css - Linux - Joomla!, drupal, worpress
2009-2010
Developer, Gipilab, Paris
Developer for Gipilab laboratory (http://www.gipilab.org). Work environment : php, html, css - Linux
2000-2004
Holiday camp activity leader, Several employers, France
Languages
English
Bilingual : Several trips in native US and Australia host families, a summer school at Stanford University.
German
Fluent : Several trips in native german host families.
Computer skills
Languages
C/C++, Java, Perl, Python, Bash, XHTML, Matlab
Web prog
php, javascript, mysql, html, css
Databases
SQL, Oracle
Analysis
UML
CMS
Joomla!, Drupal, Wordpress
Framework
J2SE, Apache, Jdbc
Softwares/Tools
Git, Unitex/Intex, Eclipse, Studio, Gimp, Photoshop
OS
Linux (Mandriva, Ubuntu, RedHat, OpenSUSE, Debian), Windows, Unix (Solaris)
Non professional activities
Lyric singing
Bass, postgraduate student in music school, member of Opus21 choir and “Comédiens de la marquise” company.
Piano
Postgraduate student in music school.
Rowing
Rowing pratice at a national level.
Selection of publications
[1]
Aurélien Bossard. Generating Update Summaries : Using an Unsupervized Clustering Algorithm to Cluster Sentences. Theory and Applications of Natural Language Processing. Springer, 2013.
[2]
Aurélien Bossard and Christophe Rodrigues. Combining a Multi-Document Summarization System – CBSEAS – with a Genetic Algorithm. volume 8 of Smart Innovation, Systems and Technologies. Springer, 2011.
[3]
Aurélien Bossard, Michel Généreux, and Thierry Poibeau. Description of the LIPN Systems at TAC 2008 : Summarizing Information and Opinions. In Text Analysis Conference 2008, Workshop on Summarization Track, National Institute of Standards and Technology, Gaithersburg, Maryland USA, 2008.
[4]
Aurélien Bossard, Michel Généreux, and Thierry Poibeau. Résumé automatique de textes d’opinion. In Agata Jackiewicz, Marc El-béze, and Susan Hunston, editors, Opinions, sentiments et jugements d’évaluation, volume 51 no 3 of Traitement automatique des langues. Hermès, 2011.
Projets
Projet ASADERA (Automatic Summarization for the All-Digital ERA)
Le projet ASADERA, financé par l’ANR sous l’appel à projets JCJC, vise à étudier deux composantes différentes du résumé automatique :
- du résumé automatique multilingue comparé : soit la synthèse des différences de traitement de l’information entre des documents traitant d’un même sujet et écrits dans des langues différentes ;
- l’impact de ressources spécifiques sur le résumé automatique de documents spécialisés.
Le projet ASADERA réunit différents chercheurs du Laboratoire d’Informatique Avancée de Saint-Denis, spécialisés dans différents domaines : traitement du langage, recherche/extraction d’information, gestion des connaissances et du raisonnement.
Projet Infom@gic (2006-2009)
Le projet Infom@gic, du pôle de compétitivité Cap Digital "Image, Multimédia et Vie Numérique), coordonné par Thalès, regroupait plus de 20 partenaires privés et publics, dont le LIPN au sein duquel j’ai effectué ma thèse.
Ce projet visait à développer et tester de nouvelles techniques de recherche et extraction d’information et de fusion d’informations multimédia. Il a été actif de 2006 à 2009.
Projet Quaero
Quaero est un programme collaboratif d’innovation et de recherche industrielle franco-allemand. Il porte sur l’analyse automatique et l’enrichissement de contenus numériques, multimédias et multilingues.
Coordonné par Technicolor, il réunit 32 partenaires publics et privés, dont le LIMSI, au sein duquel j’ai effectué un postdoctorat entre 2011 et 2012.
Démonstrateur de résumé automatique
Ce démonstrateur de résumé automatique utilise la méthode MMR, décrite dans l’excellent article de J. Goldstein et J. Carbonell, sans aucun traitement linguistique. Par conséquent, les résultats ne sont pas au niveau des résumeurs automatiques qui utilisent des ressources supplémentaires : étiquetage morpho-syntaxique, détection des entités nommées… mais peut donner un aperçu de ce que l’on peut faire actuellement avec des traitements simples. La fonction de score utilisée ici est LexRank, décrite dans l’article de G. Erkan et D. R. Radev (2004).
Pour le moment, le démonstrateur ne gère que le français. Je n’ai pas encore ajouté les stop listes (les listes qui définissent les mots vides, trop fréquents pour être pertinents) pour d’autres langues, mais c’est la prochaine étape du développement, ce avec une détection automatique des langues pour lesquelles j’aurais ajouté des stop listes.
Vous pouvez modifier les paramètres de génération du résumé pour générer des résumés de documents d’un maximum de 25.000 caractères. La qualité des données en entrée est primordiale, n’entrez si possible que des données encodées en utf-8, et des textes dont les phrases sont bien séparées par les caractères ( . ! ? )
Présentation générale
I. Généralités
Le résumé automatique est une des premières applications de traitement automatique du langage (TAL) à avoir vu le jour, avec la traduction automatique. Il s’agit pour un système de condenser un texte en entrée en utilisant des techniques variées. Un résumé automatique peut être créé de deux manières différentes :
par extraction : on va sélectionner dans les tetes d’origine les phrases les plus pertinentes à intégrer dans un résumé ;
par génération : on va sélectionner des informations issues des textes, puis générer un nouveau texte à partir de ces informations.
Evidemment, la génération est bien plus proche du raisonnement humain que l’extraction. Cependant, le cerveau humain étant très complexe, calquer ce raisonnement est un défi énorme, qui peut se rapprocher du domaine de l’IA forte. Un système fonctionnant par génération doit en effet : trouver comment modéliser des informations qui peuvent être très complexes, réussir à les extraire malgré les fortes disparités d’expression de ces informations dans les textes - on peut paraphraser quasiment à l’infini - puis recréer un texte cohérent à partir des informations extraites des textes.
C’est pour cela que la recherche s’est très majoritairement et très rapidement (sauf sur certaines exceptions, par exemple quand on cherche à résumer des textes d’un domaine et dans un format bien définis) orientée vers le premier type de méthodes : les méthodes extractives.
II. Deux grandes familles de résumé par extraction
Dans le domaine du résumé par extraction, les possibilités sont très vastes. Dès les début du résumé automatique, deux grandes familles d’approches vont émerger : les approches symboliques et les approches statistiques.
Luhn (1958) va proposer un système où les phrases sont extraites selon un score qui dépend de la fréquence de ses mots dans les textes d’origine. Il part de l’hypothèse que l’importance d’un mot peut être déduite de sa fréquence, et que l’importance d’une phrase peut être déduite de la fréquence de ses mots.
Baxendale (1959) va privilégier les phrases qui apparaissent à des positions bien définies dans les textes d’origine. En effet, certains types de documents utilisent une rhétorique immuable qui permet de déterminer l’importance d’une phrase selon sa position. C’est notamment le cas des dépêches et articles de presse, dans lesquels les phrases importantes se trouvent dans l’accroche, soit dans les premières positions.
Edmundson (1969) se concentre sur la présence de certains mots clés ; dans des documents scientifiques, par exemple, les phrases introduites par “En conclusion” peuvent être considérées comme essentielles.
Les approches proposées par les deux derniers scientifiques cités sont qualifiées de “symboliques”. En effet, elles s’attachent aux symboles (les mots eux-mêmes, ou la position d’une phrase) pour juger l’importance d’une phrase, par opposition aux approches statistiques (ici, nous avons pris l’exemple de Luhn), qui s’attachent aux fréquences.
Les indices décrits ici sont encore utilisés de nos jours par de nombreux systèmes de résumé automatique. Les différences tiennent à la façon dont on va d’une part utiliser ces informations pour extraire les phrases : les algorithmes d’extraction, et par la façon dont on gère les textes : considère-t-on des mots bruts ou regroupe-t-on les mots dans de grandes familles sémantiques ? Comment résout-on les références anaphoriques etc…
III. Centralité/Diversité
Sélectionner les phrases les plus pertinentes est nécessaire, mais n’est pas suffisant. Prenons le cas d’une méthode de résumé statistique le plus simple possible : elle élimine les mots vides (tous les mots extrêmement fréquents qui constituent la base d’une langue mais qui ne contribuent pas ou peu au sens), et considère le score d’une phrase comme la somme des fréquences de ces mots.
Ce type d’approche est valable car elle fait l’hypothèse (confirmée) que les mots les plus importants sont les plus fréquents. Cependant, une telle approche a de très fortes chances, si on limite le résumé à deux phrases seulement, de sélectionner deux phrases quasiment identiques; en effet, elles seraient composées des mots les plus fréquents.
Or, un résumé doit être le moins redondant possible, et donc maximiser la “diversité”. Si l’on considère que sélectionner les phrases les plus pertinentes revient à maximiser la “centralité”, construire un résumé consiste à résoudre le compromis “centralité/diversité”. A suivre évidemment…
Mise en ligne de la nouvelle version de l’outil de résumé automatique
Un nouvel outil de résumé automatique vient d’être mis en ligne. Développé en Java, open source et le plus modulaire possible, celui-ci permet de produire des résumés automatiques en utilisant différentes méthodes d’extraction de phrases ainsi que de modifier les composants essentiels de ces méthodes d’extraction.
Développé par Valentin Nyzam, doctorant au LIASD et recruté sur le projet ASADERA, cet outil a vocation à évoluer et sera bientôt porté en webservice. Il est disponible sur le portail github : dépôt Github de l’outil de résumé automatique.
Blog
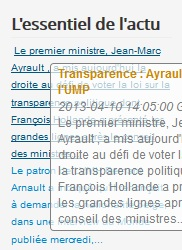
Module “L’essentiel de l’actu”
Le module “L’essentiel de l’actu” est opérationnel. Ce module sélectionne, parmi les phrases du jours de fils rss d’actualités, les n plus représentatives. Ces phrases, assemblées, peuvent être considérées comme une certaine forme de résumé de l’actualité. En effet, du fait de la stratégie de sélection, ces phrases sont centrales et leur agglomération présente non pas une même information, la plus centrale, mais un maximum d’informations parmi les plus centrales, grâce à l’algorithme MMR (J. Goldstein et J. Carbonell, 1998) et la stratégie de score du “Centroïde” (Radev et al, 2004). Je décris ici l’algorithme de ce module.
Calcul du poids des mots
Tout d’abord, les flux rss sont analysés. Des pseudo-documents sont générés, qui contiennent l’actualité des 15 derniers jours par tranche de 24h. Le tf.idf (G. Salton, 1983) des mots contenus dans le pseudo-document le plus récent (celui des 24 dernières heures) est alors calculé. Cette mesure permet de scorer les mots selon leur fréquence d’apparition dans un document et l’inverse de leur probabilité d’apparition dans les autres documents. Un mot qui apparaît beaucoup dans un document donné mais peu dans les autres aura donc un poids fort dans ce document comparé à un mot qui apparaît beaucoup dans tous les documents ou encore à un mot qui apparaît peu dans ce document.
Calcul du résumé
Ici, j’ai choisi une technique simple au regard de LexRank, utilisée dans le démonstrateur de résumé automatique. En effet, la taille des fils rss peut vite devenir problématique pour un algorithme assez gourmand, qui nécessite de calculer les similarités entre chaque paire de phrases. Aujourd’hui par exemple, l’aggrégateur de fils rss recense 373 articles, soit environ 900 phrases, et donc un près 400.000 similarités à calculer. Si cela n’est pas effrayant en soi, surtout dans un environnement idéal (bon processeur, mémoire vive suffisante, et surtout programme compilé), une technique aussi gourmande ne convient pas à une application web avec un serveur dont les ressources sont limitées. J’ai donc choisi d’utiliser la technique du “Centroïde”, bien moins gourmande, mais également moins efficace.
Génération d’un centroïde
Cette technique consiste à tout d’abord générer un centroïde. Le centroïde est un vecteur composé des mots les plus représentatifs des documents à résumer, et de leur poids. Ici, j’utilise comme poids le tf.idf, qui est également le moyen de sélection des mots. Dans l’idéal, il faudrait seuiller la sélection des mots selon leur tf.idf, c’est à dire ne sélectionner que les mots au-dessus d’un certain tfidf. Ce seuil est défini empiriquement, c’est-à-dire par l’expérience, en jugeant de la qualité des résumés produits en fonction du seuil. Cependant, à l’heure actuelle, cela fait moins d’une semaine que l’aggrégateur de flux fonctionne. Les valeurs seuils du tfidf valables aujourd’hui ne le seront sûrement plus demain. Par conséquent, en attendant que quinze jours aient passé, j’utilise un centroïde de taille fixe.
Scoring des phrases : centralité
Les phrases à résumer sont ensuite vectorisées, et une similarité est calculée entre chaque phrase et le centroïde. J’utilise ici la similarité cosinus, qui calcule le cosinus de l’angle entre deux vecteurs. Les phrases qui ont la similarité la plus élevée avec le centroïde sont donc les plus centrales vis-à-vis des documents à résumer. Cependant, ces phrases-ci ne peuvent pas constituer un résumé. En effet, leur sélection génèrerait un résumé extrêmement redondant. Il faut donc appliquer un “filtre” pour éviter la redondance.
Scoring des phrases : diversité
L’algorithme MMR permet de sélectionner des phrases en tenant compte à la fois de leur centralité, et de la diversité du résumé qu’elles génèrent. Le principe est simple : la première phrase sélectionnée est celle de score centroïde maximum. Par la suite, une phrase est sélectionnée à chaque étape, qui est de compromis maximum entre le score centroïde et la similarité avec la phrase la plus proche déjà sélectionnée.
Présentation des phrases
Une fois les phrases sélectionnées, celles-ci sont affichées. Pour les recontextualiser, mais également parce que c’est la loi, un survol d’une phrase affiche l’article dont elle est tirée, et la phrase est elle-même un lien vers cet article.
Version bêta du module de résumé de l’actu
J’ai terminé la version bêta du module de résumé de l’actualité. Ce module propose les phrases les plus représentatives de l’actualité du jour. Cependant, je ne conçois pas le résumé comme un simple agglomérat de phrases. Dans le cas d’un site web, où l’on cherche un résumé indicatif, un outil de synthèse doit pointer vers les informations originales. Ce sera bientôt chose faite, comme pour le module de nuage de mots.
Pour le moment, vous trouverez sûrement les résultats “étranges”. Je viens en effet de mettre à jour les sources d’actualité, et ajouté deux fournisseurs, et non des moindres puisqu’ils représentent à eux deux plus des deux tiers des informations d’aujourd’hui, malgré les quatre autres fournisseurs d’actualité déjà utilisés. Par conséquent, les résultats seront “étranges” pendant deux ou trois jours, le temps de constituer un historique de contenu suffisant pour ces deux flux supplémentaires.
Début du développement d’un outil de résumé automatique de l’actualité : dernière phase
J’ai fini de développer le coeur du composant de résumé automatique : le lien avec les données, et le moteur de résumé en lui-même. Il ne reste plus qu’à développer le module Joomla! permettant d’afficher tout ça.
Voilà un avant-goût de ce que vous pourrez voir (résumé des 24 dernières heures d’actu) :
Après deux jours de débat, le Sénat a adopté dans la nuit le premier article du projet de loi Taubira.
Corée du Nord : Séoul et Washington relèvent leur niveau de surveillance militaire.
L’épicentre du tremblement de terre se situe à un peu moins de 100 km au sud de Bouchehr, où se situe la seule centrale nucléaire iranienne.
Le directeur général de la banque genevoise Reyl et Cie, qui gére le compte en Suisse, non déclaré au fisc français, de Jérôme Cahuzac a été entendu à sa demande mardi à Genève par le procureur…
L’édition 2014 de son dictionnaire définit le “mariage” comme l’"acte solennel par lequel deux personnes de sexe différent, ou de même sexe, établissent entre eux une union…
On remarquera que ça fait un an que l’actu tourne autour des mêmes thèmes : le nucléaire et les tremblements de terre, le mariage pour tous, la Corée du Nord et depuis 6 mois, l’“AFFAIRE” Cahuzac. Bref, je me demande si mon outil est si utile que ça.
Correction de bug dans le démonstrateur de résumé automatique
La qualité des résumé produits par le démonstrateur étant en dessous de ce que j’ai avec les outils que j’avais développés pour moi, en utilisant la même technique et en enlevant toute analyse linguistique, je me suis posé des questions. J’ai bien fait, une “coquille” s’est glissée dans le calcul des similarités entre phrases, qui est à la base de la construction du graphe des phrases. Ce graphe permet d’établir la popularité des phrases, et d’extraire les plus populaires. La coquille est corrigée, et les résultats devraient suivre… (enfin j’espère)
Les mots de l’actu
“Les mots de l’actu” est un module que j’ai pensé, développé, et intégré au site. Il consiste en une analyse des fils rss “à la une” de diverses sources d’information. Je me suis appuyé sur magpierss, un très bon parser rss en php afin de décoder les fils rss.
“Les mots de l’actu” procède ensuite à une analyse statistique très simple des mots contenus dans les titres et les descriptions des actualités disponibles. Je parle d’analyse simple car les moyens à disposition avec l’hébergement mutualisé du site ne permettent pas de procéder à des tâches complexes, telles que de l’analyse terminologique ou de l’étiquetage morpho-syntaxique. Seuls les mots simples sont donc considérés lors de l’analyse statistiques, et non les mots composés fréquents, comme “erreur judiciaire” ou encore “abominable homme des neiges”.
Les titres et descriptions des articles sont sauvegardés pendant deux semaines. Ces deux semaines d’actualités permettent d’avoir suffisamment de données afin d’extraire les mots les plus représentatifs de l’actualité des 24 dernières heures. Des mesures comme okapi (Robertson, Sparck-Jones, 1976) ou le tf.idf (G. Salton, 1983) – utilisé ici – permettent d’évaluer la pertinence d’un mot dans un document étant donné un contexte.
Les 20 mots les plus représentatifs de l’actualité du jour sont ensuite affichés à l’utilisateur sous la forme d’un nuage de mots.
Des extensions sont prévues pour ce module, et seront implémentées rapidement. L’objectif est de fournir non pas un résumé indicatif de l’actualité à un lecteur, mais un point d’accès à l’information essentielle.
Début du développement d’un outil de résumé automatique de l’actualité
Maintenant que l’outil “Les mots de l’actu” est quasiment terminé (il ne reste plus qu’à réussir à le lancer automatiquement à intervalles réguliers par cron) je vais m’atteler à un nouveau composant.
Ce nouveau composant sera chargé de résumer automatiquement l’actualité quotidienne. Les résumés seront générés par extraction, c’est-à-dire par sélection des phrases jugées les meilleures à être intégrées à un résumé. La pertinence de l’extraction d’une phrase est évaluée selon deux critères : sa centralité vis-à-vis de l’information quotidienne (elle doit véhiculer les informations les plus importantes) et la diversité qu’elle procurera au résumé (un résumé doit éviter au maximum toute information redondante).
Yapluka !
Développement de l’outil “Aujourd’hui dans l’actu”
La première étape est franchie, j’ai développé un analyseur de fils rss et terminé les modules d’analyse statistique. Il ne reste plus qu’à attendre que les données soient suffisantes pour obtenir des résultats. L’analyseur est paramétré pour comparer les actualités à la une des dernières 24 heures de plusieurs fils d’actualité avec les actualités à la une des deux semaines qui les ont précédées. Il ne reste plus qu’à développer un module de nuage de mots pour Joomla ! et à espérer que tout ça roule tout seul. Un petit avant-goût avec les mots les plus fréquents de l’actualité des huit dernières heures :
- Trois
- affaire
- ont
- ans
- France
- Cahuzac
- Français
- monte
- Hollande
- mort
- avril
- 2
- grippe
- Nouvelle
- Pakistan
- Elysée
- Alexandre
- agence
La pondération des fréquences de ces mots, que j’effectue(rai car les données ne sont pas encore là) avec une simple mesure tf.idf (G. Salton, 1983) sur les données de la quinzaine précédente, permettra de faire descendre certains mots trop fréquents. Je pense notamment, en voyant cette liste, à “Elysée” (quoiqu’avec l’affaire Cahuzac…), “agence”, ou encore “ont” (qui bizarrement n’est pas dans ma stopliste).
A terme, je pense développer un résumeur automatique de l’actualité des 24 dernières heures, qui utilise les sorties de l’analyseur de fil rss.
Début du développement d’un démonstrateur de résumé automatique
Pour inaugurer mon nouveau site web, je développe une interface web de résumé automatique. Celle-ci sera limitée en nombre de mots à résumer et les résumés qu’elle générera seront fondés sur l’approche MMR, décrite dans l’excellent article de J. Goldstein et J. Carbonell. Cette approche est moins gourmande en ressources que l’approche que j’ai développée durant ma thèse. Tout traitement linguistique sera exclu, ce qui aura pour conséquence de produire des résumés bien moins cohérents que ce que l’on peut faire actuellement avec un minimum de traitements (étiquetage des catégories morpho-syntaxiques, étiquetage et typage des entités nommées, normalisation des dates…) Je compte ensuite proposer des interfaces de résumés spécifiques à certains types de documents, et prendre en charge des fichiers pré-annotés par les utilisateurs dans un format spécifique.
Contact
Fonction:
Docteur en informatique
**Adresse: **
1 allée du 8 mai 1945
Saint-Ouen
93400
France
http://www.aurelienbossard.fr